[ML] Paper Review: Deep Redisual Learning for Image Recognition(ResNet)
- Paper Title: Deep Residual Learning for Image Recognition
- Link: https://arxiv.org/abs/1512.03385
1
2
3
4
5
6
7
8
@misc{he2015deep,
title={Deep Residual Learning for Image Recognition},
author={Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
year={2015},
eprint={1512.03385},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Summary
해당 논문은 네트워크의 Layer가 깊어질수록 발생하는 Degradation을 다룹니다.
(Gradient Vanishing, Gradient Exploding 과 별개)Degradation은 Overfitting 이 원인이 아닙니다.
(Training Error가 증가하는 것으로 증명됨)
Degradation은 multiple nonlinear layers에 의해 Identity Mapping을 근사하는 것이 어려움을 보여줍니다. 이를 해결하기 위해 Shortcut Connection을 활용합니다.
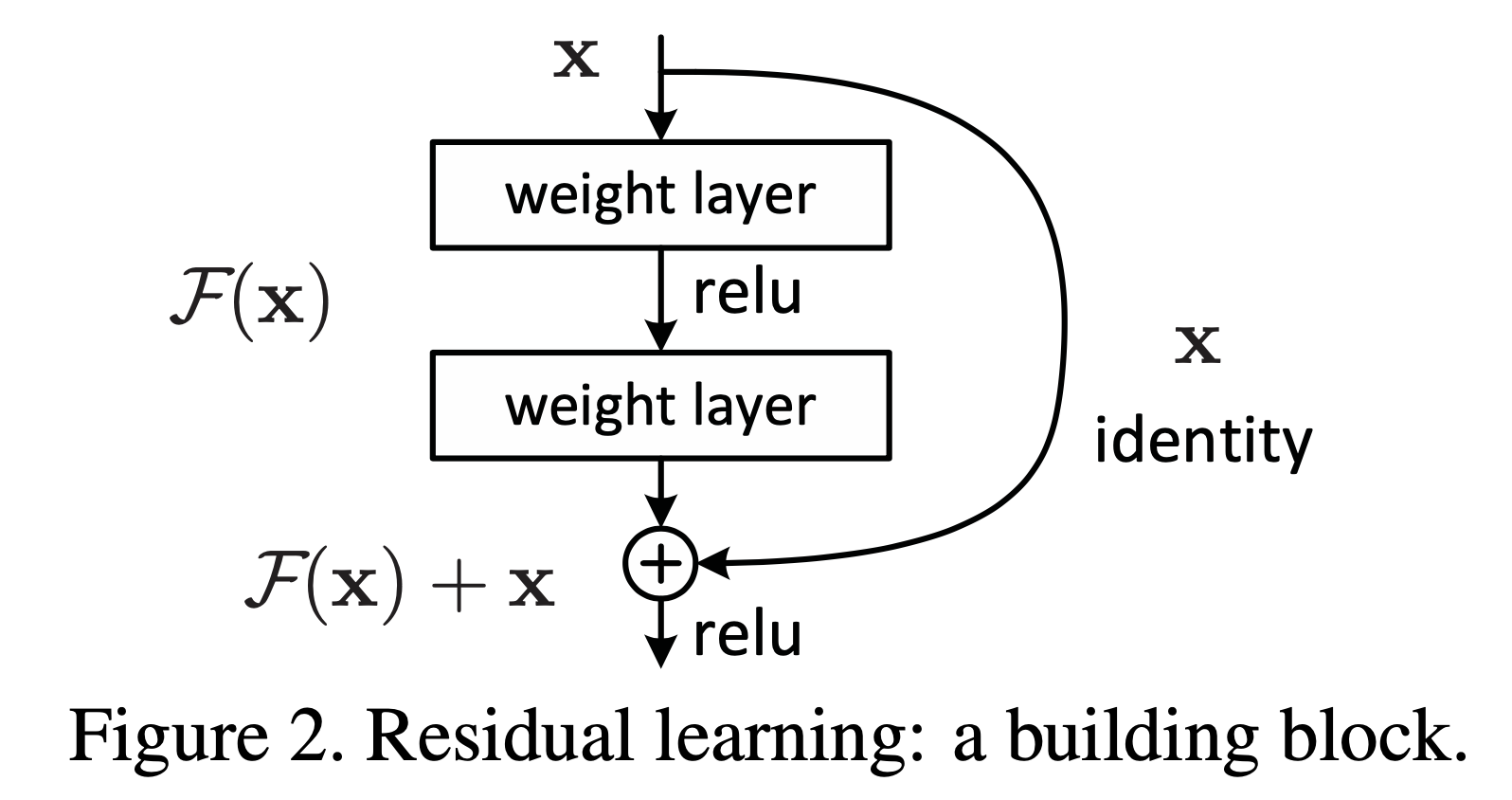 Figure 2
Figure 2
만약 Identity Mapping 이 학습시 최적일 경우, Shortcut Connection을 통해 기존의 Identity Mapping을 근사하는 것이 아니라 잔차(Redisual)를 0으로 근사시키도록 구조를 변경하였습니다.
- $ F(x) $: multiple nonlinear layers를 통과 전 값
$ H(x) $: multiple nonlinear layers를 통과 후 값
- Shortcut Connection 추가
- $ H(x) = F(x) + x $: Original Mapping
- $ F(x) = H(x) - x $: Residual Mapping
추가 설명
Identity Mapping이 학습시 최적인 경우에는 여러개의 비선형 레이어를 통과한 $H(x)$를 $F(x)$로 근사시켜야 합니다. 하지만 위에서 언급한대로 Identity Mapping으로 근사는 어렵기 때문에 Shortcut Connection을 추가하여 $H(x) = F(x) + x$ 형태로 구조를 변환시킵니다. 이럴경우 $F(x)$ 를 0으로 근사시켰을 때 $H(x) = x$ 가 됩니다.
$x$는 multiple nonlinear layers를 통과하기 전 값이며 Shortcut Connection을 통해 변환없이 그대로 전달된 값 입니다.
이에따라 $H(x)$ 는 Identity Mapping으로 근사하게 됩니다. 이 과정에서 $F(x)$ 에 대해서 식을 변형해보면 $F(x) = H(x) - x$ 가 됩니다. 이 때, $H(x) - x$는 Redisual(잔차)를 표현하는 식이되고, $F(x)$를 0으로 근사시킨 것은 결과적으로 잔차를 0으로 근사시킨 결과와 동일한 형태가 됩니다.
Intro
Network의 depth가 클수록 좋은 퍼포먼스를 보임
Network의 depth가 커지면 Gradient Vanishing 또는 Gradient Exploding 발생
→ 지금까지 Normalized initialization, Intermediate normalization layer로 addressed 됨더 깊은 Network를 converging(수렴)가능하게 되면서 새로운 문제 Degradation 발생
→ Network의 depth가 증가할수록 acc가 saturated(포화)되어 급격하게 degrade(감소)Degradation은 예상과 다르게 overfitting 이 원인이 아니다.
충분히 deep한 model에 layer를 추가하였을 때 더 높은 Training Error가 발생함을 실험에서 완전히 증명
(Overfitting이 원인이라면 training error가 증가하는게 아니라 감소해야한다.)Degradation(of training accuracy)은 모든 시스템이 유사하게 최적화하기 쉽지 않다는 것을 보여준다.
Degradation 문제를 해결하기 위해 deep residual learning framework 를 다룬다.
Figure 2
Underlying (근본적인) Mapping $ H(x) $ 로 표시된 쌓인 비선형 레이어가 있을 때
해당 $ H(x) $ 를 또 다른 Mapping $ F(x) := H(x) - x $ 로 fit 시킬 수 있다.
- $ H(x) = F(x) + x $ : Original Mapping (Unreferenced Mapping)
- $ F(x) = H(x) - x $ : Residual Mapping
- 해당 논문에서는 Residual Mapping이 더 최적화(optimize)하기 쉽다고 가정한다.
- 극단적으로, Identity Mapping 이 Optimal 일 때, 나머지(Residual)에 해당하는 $ x $ 를 $ 0 $ 으로 만드는 것이 Identity Mapping에 fit 시키는 것보다 쉽다.
- $ F(x) + x $ 는 feedforward neural network 의
Shortcut Connection으로 인지될 수 있다.(Figure 2 이미지 참조)
- Shortcut Connection: Identity Mapping
- Extra parameter (x)
- Extra computation complexity (x)
3.1 Residual Learning
Multiple nonlinear layers 가 복잡한 학습도 근사 가능하다고 가정한다면 $ H(x) - x $ (Residual Function) 도 근사 가능하다. 즉 $ F(x) = H(x) -x $ 가 근사 가능하며, Original Function 인 $ H(x) $는 $ H(x) = F(x) + x $가 된다.
Degradation은 solver가 multiple nonlinear layers에 의해서 Identity Mapping을 근사하는 것에 어려움을 가진다는 것을 보여준다. Residual Learning 재공식화를 통해서, 만약 Identity Mapping이 optimal일 때, Identity Mapping 에 가까워지기 위해서 solver는 간단하게 multiple nonlinear layer의 weight 를 $ 0 $ 으로 만든다.실제로는 Identity Mapping이 optimal은 아니지만, 우리의 재공식화는 문제의 precondition(전제조건)을 돕는다. 만약 optimal function이 Zero Mapping보다 Identity Mapping에 가깝다면, solver는 새로운 함수를 학습하는 것 보다 Identity Mapping을 참조하여 작은 변화를 더 쉽게 찾을 수 있게된다.
Architecture
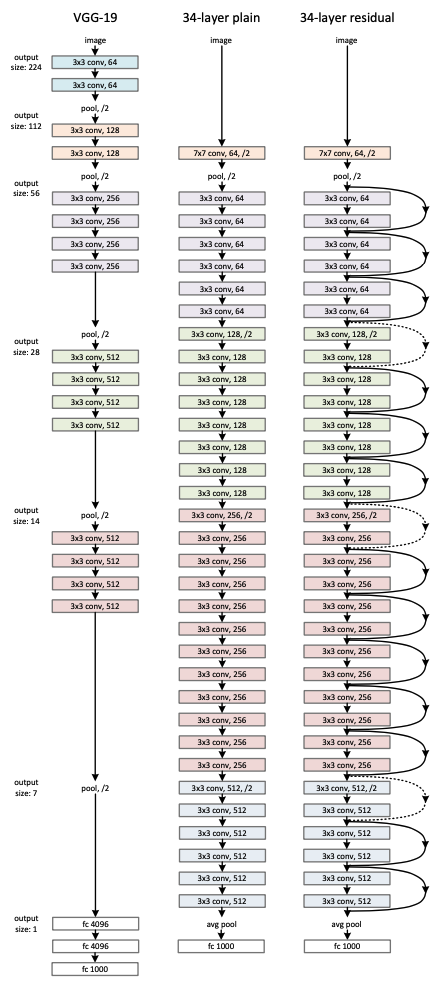 Figure 3
Figure 3
Plain Network
Feature map 출력 사이즈가 동일하면, filter 의 갯수도 동일하게 유지
Feature map 출력 사이즈가 반으로 줄어들 경우 (Conv with Stride 2),
filter 의 갯수는 2배로 증가 (Layer 마다 Time Complexity 유지를 위해)
Downsampling 은 Conv with Stride 2 만을 사용하므로 3x3 Conv 의 경우에도 padding=1 을 주어 Feature Map Size 를 유지한다.
- End of Network: Global Average Pooling, 1000-way fully-connected layer with softmax
Residual Network
- 기본적인 조건은 위의 Plain Network와 동일
- Shortcut connection 추가
Shortcut Connection
input 과 output 이 동일한 dimension일 경우(Identity Shortcut)
(Solid line in architecture image)output의 dimension이 input 보다 증가한 경우(Dotted line in architecture image)
- Option A: (Zero Padding) → No extra parameter
- Option B: 1 x 1 Conv (Projection Shortcut) → Extra parameter
해당 논문에서는 shortcut의 사용방법에 따른 성능비교를 보여준다.
(A) Increasing Dimension에 Zero Padding을 활용한 Shortcut을 사용
(나머지는 모두 Identity Shortcut)(B) Increasing Dimension에 Projection Shrotcut을 사용
(나머지는 모두 Identity Shortcut)(C) 모든 Shortcut 을 Projection Shortcut으로 사용
퍼포먼스 비교결과: A < B < C
(B is slightly better than A, C is marginally better than B)
(C) 는 extra parameter 에 의한 결과라고 언급하며, (A), (B), (C) 에서의 작은 차이를 통해 알 수 있는 것은 Projection Shortcut 이 degradation 문제를 address하는 것의 본질이 아니라는 것을 보여준다. 따라서 해당 논문에서는 모델크기, memory/time complexity를 줄이기 위해 (C) 를 사용하지 않는다.
Deeper Bottleneck Architectures
Residual Block For Bottleneck (3 Layer)
Layer 가 깊어지면 training time 이 증가하는 것을 고려하여 Residual Block을 개선
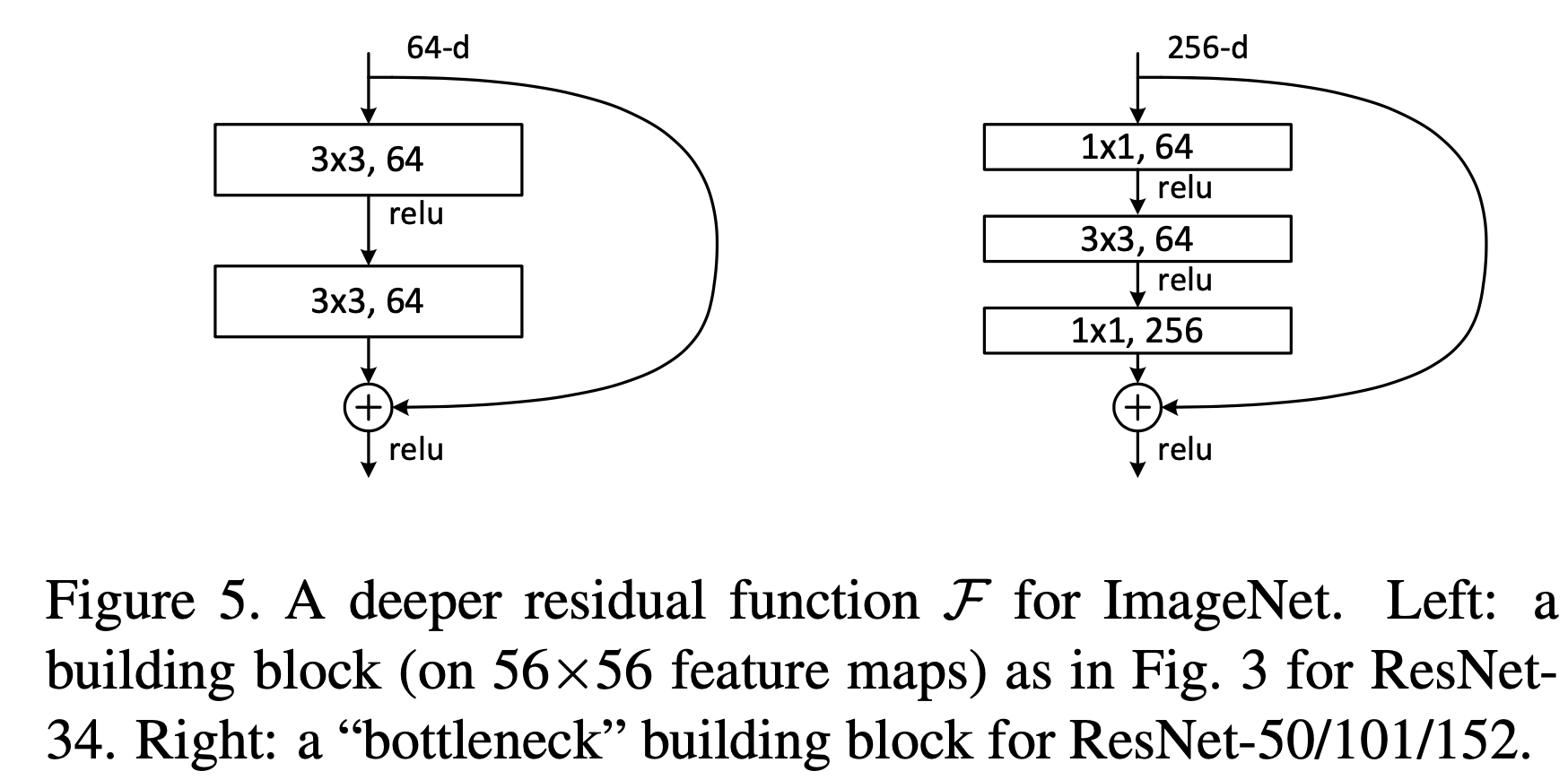 Figure 5
Figure 5
- 1 x 1 Layer: Dimension을 줄이고 늘리는(복구하는) 것을 담당
- 3 x 3 Layer: leaving the 3×3 layer a bottleneck with smaller input/output dimensions
- Identity Shortcut (parameter-free) 가 bottleneck architecture 에서 중요하다.
Identity shortcut 이 projection(1 x 1 conv)으로 대체될 경우 time complexity와 model size 가 두배로 증가할 수 있다.
Number of Layers
 Table 1
Table 1
Residual Unit(3x3, 3x3) 을 사용할 경우 (unit 갯수 * 2) + 2 (Init Conv, FC)
(18-layer,34-layer에서 사용, Table 1 참조)Bottleneck Residual Unit(1x1, 3x3, 1x1)을 사용할 경우 (unit 갯수 * 3) + 2 (Init Conv, FC)
(50-layer이상부터 사용, Table 1 참조)
Subsequent Paper
Paper Title: Identity Mappings in Deep Residual Networks
1
2
3
4
5
6
7
8
@misc{he2016identity,
title={Identity Mappings in Deep Residual Networks},
author={Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
year={2016},
eprint={1603.05027},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Summary: Identity Mappings in Deep Residual Networks
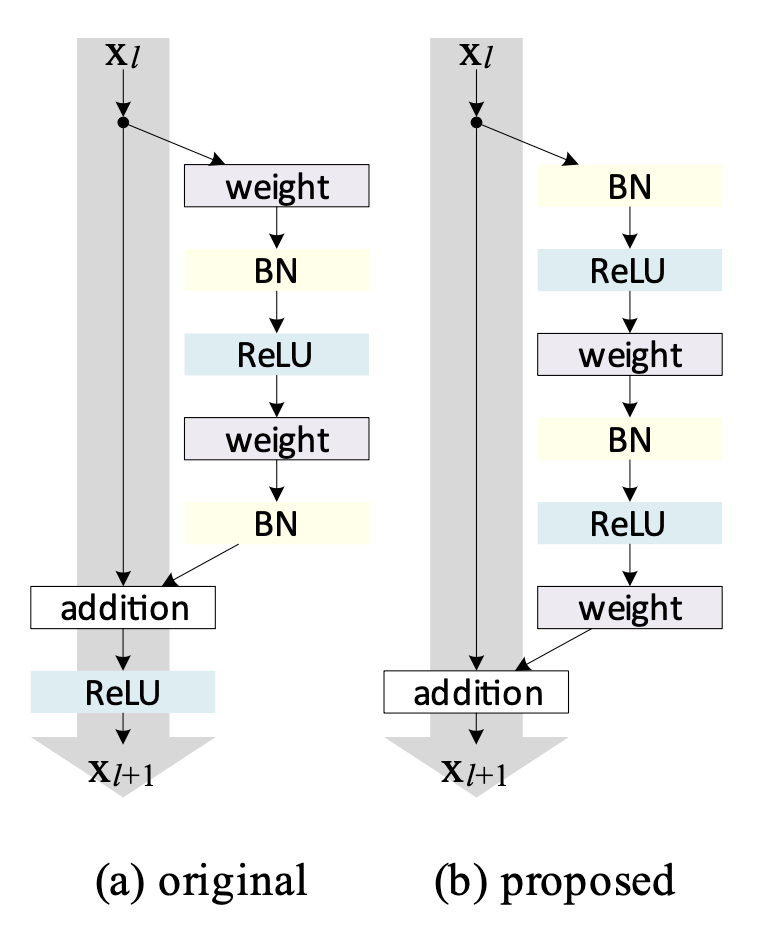 Identity Mappings in Deep Residual Networks: Figure 1 Left
Identity Mappings in Deep Residual Networks: Figure 1 Left
Shortcut Connection의 값은 변환없이 “Clean”하게 유지하는 것이 최적화에 유리
(a) original의 경우 skip connection path 에ReLU가 있어 (b) proposed 보다 clean하지 못하다.- (a) Post-activation (original)
- Form: Conv3x3 + BN + ReLU + Conv3x3 + BN + (Shortcut connection) + ReLU
- (b) Pre-activation (Proposed)
- Form: BN + ReLU + Conv3x3 + BN + ReLU + Conv3x3 + (Shortcut connection)
ResNet Code Implementation with Pytorch
- GitHub Link: devbruce/torch-implementations: resnet.py